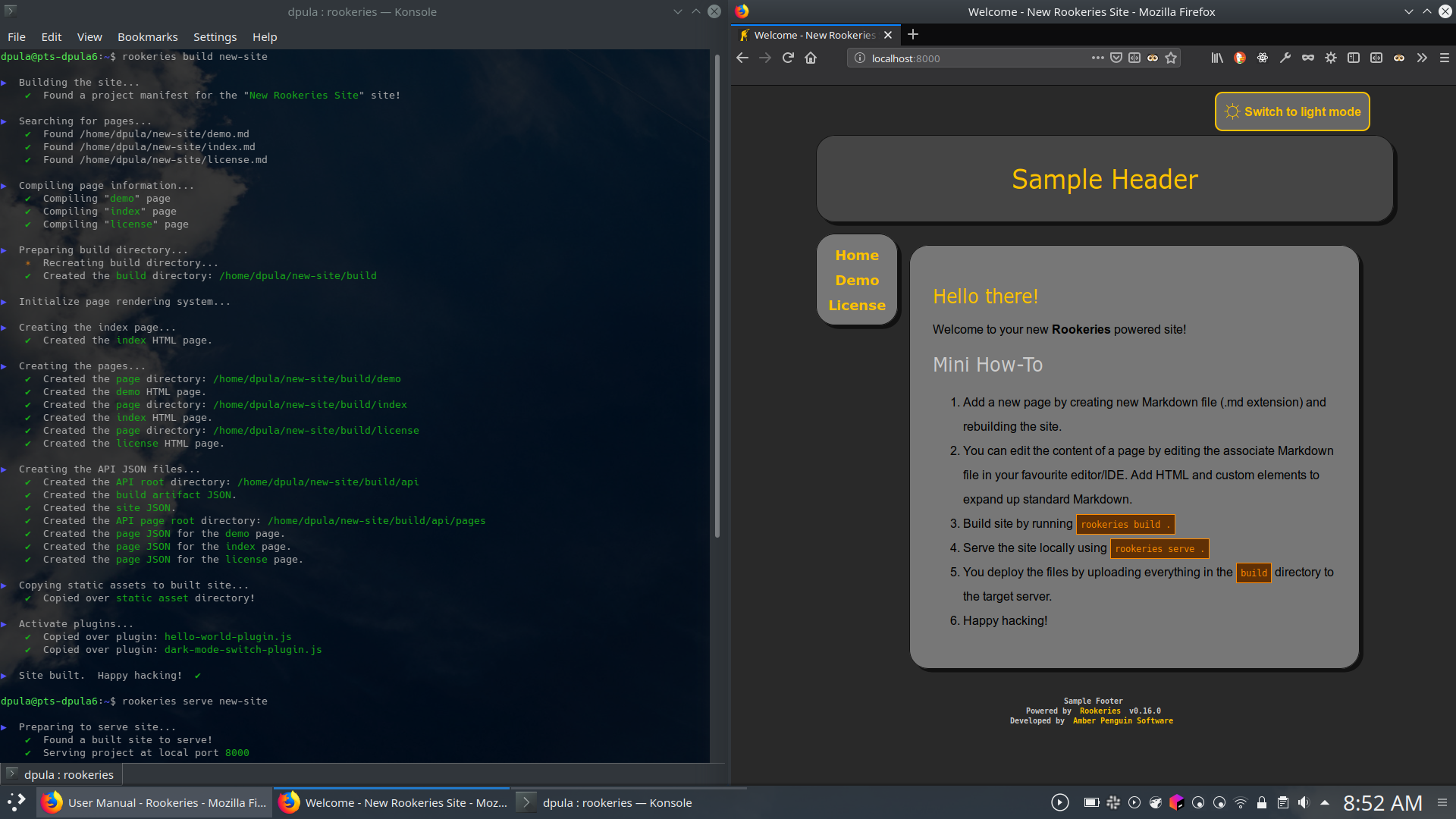
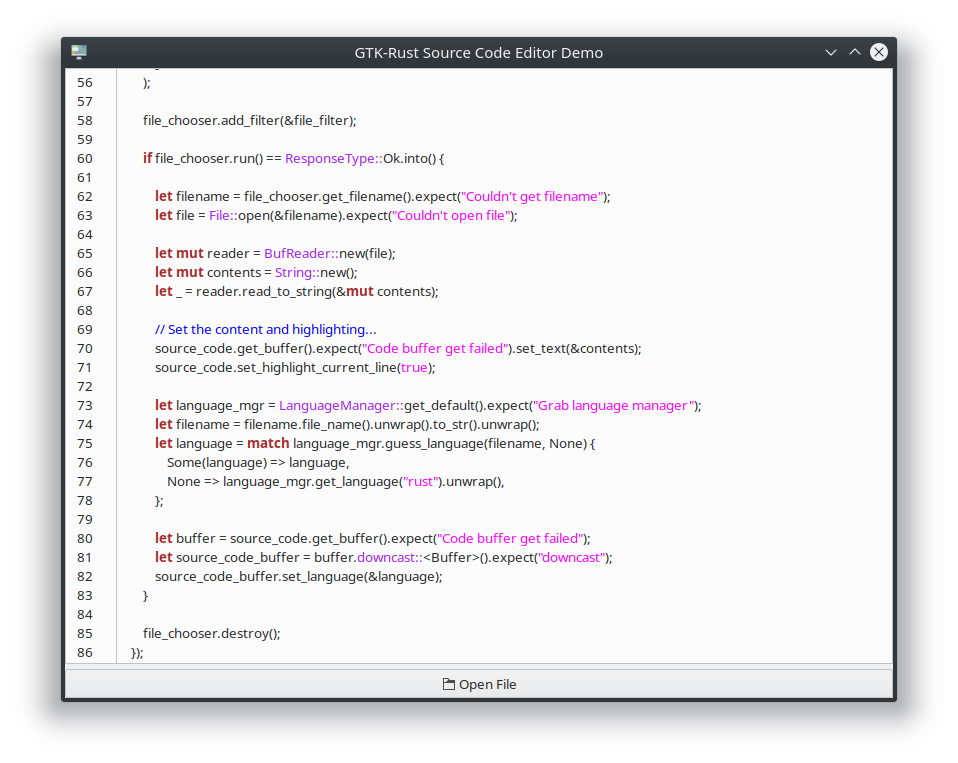
This week I am juggling a number of things related to PyCon Canada, and life
in general. Also I came to the realization in the past few weeks, that if I
want to effectively work on long term projects like Rookeries, writing
about tooling, working on my side adventure, et cetera, without burnning
out I need to have the time, space, and health to do so effectively in the long
run.
Still it felt wrong to break my writing/publishing schedule, just because I am
figuring things out. After I want to work on my output consistency while still
performing my normal day-to-day activities. Rather than force myself to rush
through the more technical post on Rookeries, I will something simpler.
Today I want to discuss some guidelines that have I adopted that help me get
better at creative work. Since both technical writing and programming are
ultimately creative work, the ideas I want to look at apply to them as well.
Schedules and Commitments
Creative types (e.g. writers and coders) often avoid schedules like the plague.
Yet I would agree you need both schedules and commitments (i.e. deadlines).
These push you to perform and ship real work. The more often you ship, publish,
release, so on, the more experience you gain and the better you become as a
professional creative. You need that feedback from your audience, client or
end-user, and you can only gain that by releasing your work to them.
Often you need external motivation to get something out there. Otherwise
you may engage endlessly in either procrastination or polishing something that
is already ready. Consistent commitments (like my own weekly journal post) help
you build that habit of shipping regularly. I would argue that regular shipping
is what differentiates a true professional creative and a wannabe. So embrace
those schedules and commitments!
Good Workflows and Environments Help You Get into the Flow
Creative output is the greatest when you are in the flow of things. Output
becomes natural, and you become more productive. However distractions can
easily pop you out of flow. If your tools, workflow or work environment
become the reason for distractions, then you will have a rough time creating.
Investing in a good workflow–tools and process that make you effective–pays
large dividends. In my case I figured out that Markdown and a good text editor,
makes me the most productive when writing. The ultimate reason for my creating
Rookeries is to create a better workflow for me when I work on websites.
Also finding the right environment to work improves creative output.
Environment includes both the physical and mental space. Hence putting on
the right music gets me into the flow than listening to the ambient noise of
an open office. (Actually I have a whole rant on why open office spaces are
the worst for creative work but that will be for another time.) Unfortunately
I do not currently have the luxury of adapting my work environment too much,
but if you have that option you should take it.
Stay Healthy
Staying healthy is one area that I often neglect to think about as a creative.
I get too caught up in the work, to remember to care of myself as well as I
ought to. The truth is that you can not consistently crank out great work when
you are sick, tired, unfocused, under the influence, or distracted by other
issues. Even if you try to push through say a cold while doing coding, you
generally find the results less than satifactory after the fact.
Physical fitness is important since you are human and you have a physical
component. That is why regular exercise, healthy food, regular rest, etc.
help with creative productivity. If you are not healthy, you will not have the
good enough energy levels for creative work.
Also as a human creative, you need to work on your mental and spirtual fitness
as well. Very few creatives can work outside of a supportive environment. I
could not imagine being productive without the support of my family, friends,
and colleagues. Also the less worries you have, the easier it will be to focus
on creative work.
Summary
I will summarize simply saying that if you want to maintain a creative
profession (writing, art, music, programming, etc.), you need to stick to
schedules and commitments to ship work regularly. Investing in a good
environment to work in will pay huge dividends. And stay healthy so that you
can continue to do the work you love for many happy years to come.